
by Malcolm Murray
 The battle lines are drawn. AI safety is fighting a battle on three fronts.
The battle lines are drawn. AI safety is fighting a battle on three fronts.
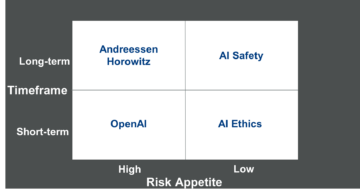
The figure shows how the AI safety viewpoint is opposed to three others, on two dimensions. First, let’s define the axes. The debate over advanced AI and its risks and benefits has many dimensions, but here we focus on two of the most important: timeframe – short-term vs long-term and risk appetite – high vs low. Timeframe is self-explanatory, but we should note that long-term here doesn’t mean the very long term measured in decades and centuries, just anything beyond the short cycles elsewhere – the quarterly earnings cycles of corporations, the valuation cycles of startups and the election cycles of politicians. Risk appetite means the level of risk one is willing to take to receive benefits. A high risk appetite means one is willing to take a large amount of risk to receive rewards, while a low risk appetite means a more risk-balanced approach, where one is willing to take a moderate amount of risk to receive the same level of rewards.
Using these two axes, we can distinguish four distinct AI viewpoints. I call these viewpoints rather than camps or groups, since several quadrants have multiple groups which may not fully agree with each other, and there is also overlap between the quadrants. The figure also contains just one prominent example for each quadrant, there are many others that could be plotted.
Let’s then turn to AI safety and the three battle lines. The AI safety viewpoint is in the top right corner, with a long time horizon and a low risk appetite. This can be loosely defined as the view that advanced AI, while bringing significant benefits to society, also poses significant new, and enhanced risks. It does not hold that all risk is bad and society should not make any progress, but rather that progress should be risk-balanced, taking into account the benefits, and weighing them against the risks. The three battle lines are with the opposing viewpoints in the other three quadrants.
The battle lines vary in their level of conflict. A year or two ago, the temperature ran highest in the battle over timeframe between the risk-cautious viewpoints. People like Timnit Gebru and Joy Buolamwini were frequently featured in the media. Their arguments don’t deny the presence of risk that should be dealt with before blindly proceeding, so they fall on the right side of the spectrum. However, they are focused on the short-term – the risks they focus on – AI ethics, bias, fairness, discrimination – are here and now. They point out, rightly, that AI is made with datasets that include all biases humanity displays and has displayed – biases in terms of gender, race and sexuality. AI therefore reflects these back to us, since as Ted Chiang says, it’s a blurry jpeg of the web.
This spring, the action moved to the battle between the two diagonally opposing viewpoints, differing both in timeframe and risk appetite. We saw this play out very visibly at OpenAI, where key people either left the company, got fired, or changed jobs. Going into 2024, OpenAI had three risk teams, as laid out in its Preparedness Framework. By summer, two of these were all but gone – the Superalignment team was completely disbanded and the future of the Preparedness team was unclear with its head reassigned.
Right now, the battleline with the most action is between the two top quadrants. The specific flashpoint is SB-1047, the California bill that aims to ensure AI developers take appropriate AI safety measures. The top left, which can be exemplified by Andreessen Horowitz and its Techno-Optimist Manifesto, is against the bill, arguing that it will limit innovation. Their main argument seems similar to the classic Republican argument against gun control – the blame should not fall on the AI, but the person using the AI. The top right argues that the bill strikes a risk-balanced stance, since it only introduces limitations on the most advanced models and only clarifies liability that mostly already exists from other legislation.
What will be the situation going forward? It seems to me that some of these battlelines could more easily be dismantled than others. For example, the right-side battle between AI ethics and AI safety could perhaps find common ground in the “lock-in argument”. The AI safety camp is worried about societal features getting locked in when advanced AI is in place. For example authoritarian rule. The AI ethics camp could potentially also frame their concerns in this way. They are justly concerned with the discrimination of today, but surely they also worry that we are training AI models on inherently biased data and that this data may form the foundation for AI models for a long time to come. Therefore, we may impede the moral arc of history that has brought us increased freedoms for races, genders and sexualities, by building bias into the system, making it impossible to remove. Similarly, efforts have been made in the AI safety camp to reduce the initial long-term aspects of their arguments and show that many of the risks they care about are just years away. The truly existential risks (as laid out e.g. here) may still be decades or centuries away, but the risks of using AI for biological weapons, cyberattacks or disinformation are risks for the 2020s.
Similarly, the top two quadrants both share a long-term perspective. Even as it brands people like me (as a risk manager) as evil, Andreessen’s manifesto is laudable in that it takes a long-term perspective. They call risk management evil, but what they really oppose is risk mitigation. Risk assessment comes before risk mitigation – we need to understand the risks before we decide what to do about them. The AI safety camp, although keen to also put in place mitigation, would not be opposed to better understanding the risks from AI. There is therefore potential common ground in regulation and policies that seek to understand the risks from AI better. For example, there is a great need for an inter-disciplinary effort to assess the levels of the different AI risks now and to forecast their levels in the future. Further, the fact that a philosophical movement (effective accelerationists) has been created in the top left corner, mirroring the effective altruists of the top right, also shows a philosophical bent. This means that the two sides could perhaps engage on logical arguments instead of only focusing on commercial and political constraints.
The quadrants that might be the hardest to reconcile are the ones that are diagonally opposed – short-term risk-seeking vs long-term risk cautious viewpoints. The most extreme of these can be illustrated by the Pause AI letter (which would be in the very top right corner) and Meta’s strategy of “open sourcing until AGI” (in the very bottom left). Unfortunately, for this battleline, it is harder to see future common ground and the battle seems likely to continue for the foreseeable future.
Enjoying the content on 3QD? Help keep us going by donating now.