
by Joseph Shieber
Discussions of artificial intelligence are hard to avoid. A recent Pew study, for example, found that 90% of Americans have heard at least something about artificial intelligence – which is astounding, when you consider that only about 70% of Americans likely know who the current Vice President is.
Despite this growing awareness of AI, it is quite possible to argue that, if anything, people are too slow to recognize its potential. That same Pew study noted that only 18% of all US adults have tried ChatGPT. This is disturbing, given how wide-ranging the effects of AI promise to be.
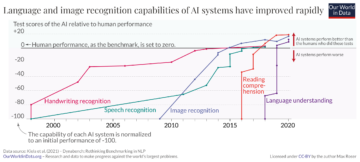
For example, as summarized by a recent explainer by Our World in Data, the capabilities of AI systems have improved remarkably in just the past 10 years – particularly in the areas of reading and language comprehension.
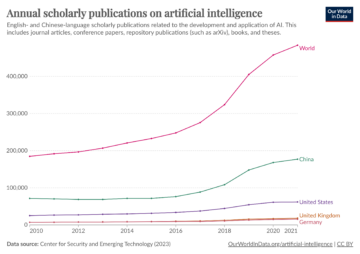
This increase in the capacities of AI systems has been mirrored by increased academic interest in artificial intelligence, with the numbers of scholarly publications related to AI more than doubling in the previous decade.
Since I’m going to be arguing that these systems are neither artificial nor intelligent, it will be useful to designate them differently. I’ll call them LLMs, or large language models.
I’ll focus most on the question of whether LLMs are intelligent, but it actually seems odd to term them “artificial” as well. Consider other tools that we employ to simplify our lives – washing machines, robot vacuum cleaners, or cars, say. We don’t call our washing machines “artificial;” nor do we say that we drive artificial cars. The reason for this is that such tools aren’t fake or phony. Rather, they’re genuine aids that make our lives easier.
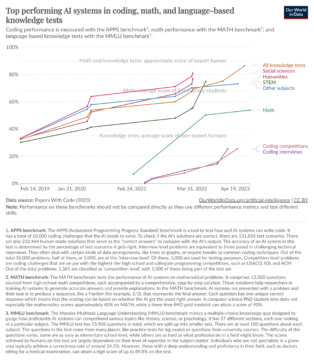
When you contemplate the remarkable advances of LLMs, it’s hard to deny that such systems are also genuine aids that promise to make our lives easier in a variety of ways. For example, the top performing large language models continue to improve at a rapid pace, achieving scores that are increasingly closer to the performance of human experts on benchmark tests of general and domain specific knowledge; though such systems still lag behind in problem-solving ability in mathematics and coding, large language models continue to make strides in those areas as well.
So it’s actually a misnomer to refer to such systems as “artificial;” far from being fake or phony, they are genuine tools with potentially wide-ranging applications. Given this, however, and considering the remarkable benchmarks these systems have already achieved, it might seem strange to suggest that these systems, though widely referred to as “artificial intelligence,” are in fact not intelligent. Let me explain why I think that it is in fact a mistake to use the term “artificial intelligence” to refer to these systems.
First, let me say how I won’t be arguing against the intelligence of LLMs. I won’t be appealing to the fact that “LLMs cannot understand, interact with, or comprehend reality” (as a recent article summarized the views of Meta’s chief AI researcher Yann LeCun). Nor will I be arguing that the lack of intelligence of LLMs stems from the fact that they are not embodied (as the philosopher and cognitive scientist Anthony Chemero has suggested). I also won’t highlight the fact that LLMs are incapable of conscious experience to establish that they aren’t intelligent (as the AI researcher Michael Wooldridge seems to argue, when he laments that “LLMs have never experienced anything. They are just programs that have ingested unimaginable amounts of text. LLMs might do a great job at describing the sensation of being drunk, but this is only because they have read a lot of descriptions of being drunk. They have not, and cannot, experience it themselves.”)
The closest argument I’ve seen to the one that resonates with me was in a recent Substack post by Arnold Kling. In that post, Kling suggests that LLMs cannot be intelligent because intelligence “is not a thing at all. It is an ongoing process. It is like science. You should not think of science as a body of absolute truth. Instead, think of the scientific method as a way of pursuing truth.”
Borrowing from Jonathan Rauch, Kling calls intelligence – the process by which we seek truth and avoid error – the “Constitution of Knowledge.” He suggests that LLMs “are not the artificial equivalent of the process of improving knowledge” because “they do not perform the functions of the Constitution of Knowledge—trying new ideas, testing them, keeping what works, and discarding the rest.”
Kling’s point is obscured by his emphasis on the nature of knowledge as a process, and by his focus on four main features of human intelligence: (1) it is collective, (2) it is not settled, (3) it is evolutionary, and (4) it is guided by institutions.
These observations are misleading, because LLMs either share these features, or these features don’t seem central to intelligence, or both. Certainly large language models themselves involve processes. Given that the datasets on which large language models are trained encompass the entirety of all of the text on the worldwide web, it would be hard to argue that LLMs are not collective or that they are not guided by institutions. Nor do LLMs treat knowledge as settled; if you’ve ever interacted with an LLM, then you know that they are willing to concede mistakes and are open to correction.
Now, it is true that LLMs are not evolutionary. Because large language models employ pre-defined algorithms that are then revised through training against the dataset, they are not a good analogue to evolutionary processes. However, though large language models are not evolutionary, they serve analogous functions. Consider the evolutionary case – say, for example, markets. Markets can also be thought of as optimization functions — that optimize price efficiency, let’s say, but they do so through evolutionary means. Large language models optimize for predicting text strings, but they do so using gradient descent.
Kling’s discussion of intelligence as a collective, unsettled, evolutionary process that is guided by institutions fails, then, to pick out what it is that disqualifies large language models from aptly being characterized as involving intelligence. Rather than focusing on any of these qualities of intelligence, we need instead to emphasize the goal of intelligence. Ideally, when we try new ideas, test them, keep what works and discard the rest, as Kling puts it, we are aiming at truth. In contrast, when the LLM tries new predictions, tests them, keeps what works, and discards the rest, it is aiming at completing some string of text in a way that will best fit with the training data.
Here’s a stab at explaining the difference. Since large language models predict what text is most likely to follow from a given string of text, it would be a mistake to think that large language models search for true representations of the world. Rather, it would be better to think of them as searching for plausible responses to questions — that is, responses that one would be most likely to receive.
If this is correct, then the reason why large language models are not intelligent is that they aim at the wrong goal. Rather than seeking accurately to answer a given question, they seek accurately to predict how humans would answer that question.
I’ll leave it to Claude.ai to sum up this point:
