
by David J. Lobina
Where was I? Last month I made the point that Artificial Intelligence (AI) – or, more appropriately, Machine Learning and Deep Learning, the actual paradigms driving the current hype in AI – is doomed to be forever inanimate (i.e., lack sentience) and dumb (i.e., not smart in the sense that humans can be said to be “smart”; maybe “Elon Musk” smart, though).[i] And I did so by highlighting two features of Machine Learning that are relevant to any discussion of these issues: that the processes involved in building the relevant mathematical models are underlain by the wrong kind of physical substrate for sentience; and that these processes basically calculate correlations between inputs and outputs – the patterns an algorithm finds within the dataset it is fed – and these are not the right sort of processing mechanisms for (human) sapience.
These were technical points, in a way, and as such their import need not be very extensive. In fact, last time around I also claimed that the whole question of whether AI can be sentient or sapient was probably moot to begin with. After all, when we talk about AI [sic] these days, what we are really talking about is, on the one hand, some (mathematical) models of the statistical distributions of various kinds of data (tokens, words, images, what have you), and on the other, and much more commonly, the computer programs that we actually use to interact with the models – for instance, conversational agents such as ChatGPT, which accesses a Large Language Model (LLM) in order to respond to the prompts of a given user. From the point of view of cognition, however, neither the representations (or symbols) nor the processes involved in any of the constructs AI practitioners usually mention – models, programs, algorithms – bear much resemblance to any of the properties we know about (human) cognition – or, indeed, about the brain, despite claims that the neural networks of Machine/Deep Learning mimic brain processes.
Modern AI [sic] is, in a way, glorified statistics, in the same way that a flat white is a glorified caffellatte – actually, a flat white is a badly made cappuccino, but the analogy still holds up: a former friend once joked that Mitt Romney seemed like a botched connectionist attempt at building a president. And as with Romney, probably, there is really nothing there; a chatbot such as ChatGPT doesn’t “know” any language, or any aspect of language, and it doesn’t “know” how to reason, either, certainly no more than a calculator “knows” how to, er, well, put two and two together (maybe the calculator understands the metaphor, though).[ii]
Indeed, and as stressed last month, deep neural networks connect an input with an output on the basis of the gigantic amounts of data they are fed during so-called “training”, when the relevant correlations are calculated. In the case of LLMs such as ChatGPT (note that I’m conflating an LLM with the “dialogue management system” that queries an LLM; will come back to this), the model predicts one word at a time, and only one word at a time every single time, given a specific sequence of words (that is, a string of words), and without making any use of the syntactic or semantic representation of the sentences it is inputted.
That is, LLMs calculate the probability of the next word given a context (as mentioned, a string), and it does so by representing words as vectors of values from which to calculate the probability of each word (via a logistic regression and some other computational processes), with sentences also represented as vectors of values. Since 2017, most LLMs have been using “transformers”, which allow the models to carry out matrix calculations over these vectors, and the more transformers are employed, the more accurate the predictions appear to be – GPT3 has some 96 layers of such transformers, for instance, and is marked improvement upon previous models and most of the competition. So, then, nothing to do with knowledge of language as the linguist understands this term, surely.
But is the view from cognitive science, or from philosophy, for that matter, so clearcut as my own take would have it? Alas. Just recently, the journal Behavioral [sic] and Brain Sciences published a call for the submission of commentary proposals on a target paper that argues that language-of-thought accounts of cognition are re-emerging, and in making this argument the authors (three amigos) consider various examples of Machine/Deep Learning models as possible alternatives. I was curious about the language-of-thought part, as readers of this blog might have guessed, and even curiouser about the bit regarding Machine Learning. After reading the article, however, it seemed to me that the three amigos (three philosophers, for the most part) had missed a step when discussing deep neural networks, coupled with a curious stance towards language and linguistics, even though various features of natural language creep in throughout the paper, and so I submitted a Commentary Proposal to fill the gap, as it were. I obviously didn’t get in, but I can leave my mark here at least. So:
Comment on Best Game in Town: The Re-Emergence of the Language of Thought Hypothesis Across the Cognitive Sciences, by Jake Quilty-Dunn, Nicolas Porot, and Eric Mandelbaum.
David J. Lobina, February, 2023
In arguing for a language of thought (LoT) architecture for cognition, Quitly-Dunn et al. mostly focus on data from three sources to make their argument: certain aspects of vision, the cognitive abilities of nonverbal minds (namely, reasoning with physical objects in infants and nonhuman animal species),[iii] and so-called System 1 cognition (namely, the use of heuristics in reasoning). This is in contrast to employing evidence from language and linguistics to unearth properties of conceptual representations, a venerable approach and the usual way to go about researching the LoT in the past.
I should note, as I have done in the past (for instance, here), that the phrase “the language of thought” can refer to two related but slightly different ideas, and one need not hold both views. One idea is the claim that most of our thinking doesn’t take place in a natural language but in a conceptual representational system – an idea that is certainly time immemorial and that, I gather, many scholars would not quibble much with (I have always had the intuition that many philosophers prefer to use the term “mentalese” when adopting this stance, as to not commit to the second idea, to be introduced presently). The other idea, much more controversial, and the position Quilty-Dunn et al. are most concerned with, at least in part, is the claim that some, or perhaps even most, psychological processes involve operations over symbolic representations that are only sensitive to the syntactic properties of these representations.
Jerry Fodor, he who is most associated to the LoT tout court, certainly subscribed to both ideas, and so he could, on the one hand, argue that some aspects of language processing and visual perception are to be explained in terms of the second position, while on the other, point to William of Ockham in relation to the first idea, only to feel a little bit blasé about his own take on what the language of thought must be like – after all, Ockham had already argued in the Middle Ages that the verbum mentis could not be semantically or syntactically ambiguous, and this is an all too common point about the LoT.[iv]
Nevertheless, Quitly-Dunn et al. explicitly state that they are putting the case of language to one side in their paper, even though various features of language are mentioned throughout, in particular, and curiously, to outline the very properties of the LoT they focus on in the paper – to wit, constituent structure, predicate-argument structure, logical operators, etc. The lack of a focused discussion on language looks like a missed opportunity to me, though, especially as a way to properly frame the relevance of neural networks to cognitive science.[v]
I take one of the main lessons to be derived from the (generative) study of language to be, not only that we must postulate a rich and intricate structure in our theories of linguistic knowledge, what linguists call “competence”, that body of linguistic knowledge comprising structured representations and principles; we must also stress the importance of what has been called the “strong generative capacity” – that is, the generation of structured presentations. This is in contrast to the generation of strings of elements, what has been termed the “weak generative capacity”, and which has proven to be rather important to computational linguistics and formal language theory, and of course to LLMs, though it does not capture the psychological reality of mentally represented grammars.
Nevertheless, some cognitive scientists seem to believe that LLMs demonstrate mastery of linguistic rules – mastery, that is, of the linguist’s competence, at least to some extent. Such a position would appear to run counter to what LLMs are and do, which is of course very different to the linguist’s theory of competence (I provided a primer of such theories here, within the context of what linguistics could offer to the study of nationalism; as part of a series of 6 posts on this topic, no less). I blame “prompt engineering”, really.
I have here stressed the point that what LLMs do is predict the next word given a string of words as a context – next token prediction, that is – but this is obviously not what a user experiences when dealing with ChatGPT. This is because ChatGPT is a “dialogue management system”, an AI “assistant” that queries the underlying LLM so that the commands and questions the user poses elicit (or prompt) the right output from the LLM, which in every single case will be a single word, word by word. An LLM, after all, is nothing more than a mathematical model plus a set of trained “parameters” (the sought-after weights of the aforementioned vectors and matrices). As the computer scientist Murray Shanahan has put it in a recent paper, when one asks an LLM who was the first person to walk on the moon, for instance, what the model is really being asked is something along the lines of:
Given the statistical distribution of words in the vast public corpus of (English) text, what words are most likely to follow the sequence “The first person to walk on the Moon was”?
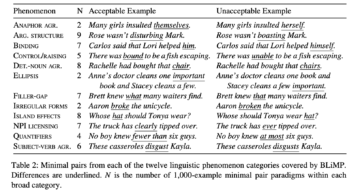
And ChatGPT would reply…(go and ask it yourself!). The trick is to embed an LLM within a larger system that includes some background “prefixes” to coax the system into producing conversation-like behaviour (e.g., a template of what a conversation looks like), but the LLM itself simply generates sequences of words that are statistically likely to follow from a specific prompt. It is through the use of prompt prefixes that LLMs can be coaxed into “performing” various tasks beyond dialoguing, such as reasoning or, as in the case of those cognitive scientists who believe LLMs can learn hierarchical structures and various other features of competence, behave as if they were participants in a psycholinguistic experiment and even provide grammatical judgements on specific strings (the photo heading this post shows some of the yardsticks against which LLMs are judged in this literature, though these are rather simplistic tests and a million years away from the richness of our actual linguistic knowledge).[vi] But the model itself remains a sequence predictor: it does not manipulate structured representations in any way, and it certainly has no understanding of what anything means – and “meaning” is an important factor, as syntax is not merely a generator of strings, but of structures that are put together on the basis of how the language faculty interacts with what are sometimes termed the conceptual/intentional, or thought, systems.
Going back to the three amigos, then, my point is simply that deep neural networks are not models of cognition; Machine/Deep Learning isn’t a theory of cognition, nor can it be, and it seems like a fool’s errand to seek any of the properties of human cognition – of the LoT, that is – in such networks. As last month’s Pylyshyn-via-Lobina put it, current neural networks are, at best, weakly equivalent to human cognition, and that’s not saying much. As stressed, and ad nauseam, in fact, neural networks are input-output correlation machines put together through an exercise in curve fitting; such networks produce input-output pairings, which they derive from the patterns they identify in human-created datasets. No more than that, and not how cognition in fact works.
Interacting with a conversational agent such as ChatGPT clearly creates a compelling picture, and one that yields the illusion that one is interacting with a cognitive agent – an engineering feat, no doubt – but an illusion nonetheless and the result of ascribing, nay, projecting, mental states to mathematical models and computer programs, which is absurd. This unhealthy case of anthropomorphism is all the more common in the popular press, where one constantly reads about an AI agent that has created a piece of art, or made a discovery in biology, when in actual fact what happened in every case is that some engineers designed a mathematical model for the very purpose that is described. But the thing remains a tool; the technology will be misused if we misuse it, but talk of the singularity and the like (and, let’s be frank, of self-driving cars), is really science fiction.
[i] I’m only judging by the content emanating from the eponymous Twitter account, of course, which can certainly give any chatbot developer out there a run for their money.
[ii] I can only hope that my use of “[sic]” after AI is clear by now; it signals two things: that by AI most people mean Machine/Deep Learning, even though there are other methods available in AI; and, also, that the operations of the better known AI systems are, technically speaking, quite dumb and hardly qualify as “intelligent” under any meaningful understanding of the term. My other use of “[sic]” in last month’s piece, after the phrase ‘cold-cut revenge’, was a reference to the TV show The Sopranos and was meant as a joke, though I fear no-one got it (or cared!). I use “[sic]” a few more times in this post, not least two paragraphs below in the main text, but in that case it is because US spelling is simply wrong. Speaking of which: caffellatte is not misspelled, in case anyone was wondering.
[iii] It is dubious that there is such a thing as a nonverbal infant, actually, at least not strictly speaking; what is usually meant by this phrase is, I think, the developmental fact that children don’t start vocalising what looks like language until the age of 12 months or so, proceeding slowly thereon. However, infants start acquiring language practically from birth, especially some aspects of phonology, and in this sense even newborns are “linguistic creatures”. Infants are also sensitive to complex, syntactic properties at an age where they are nowhere near being able to produce the respective sentences, as demonstrated by the use of comprehension tasks such as the preferential looking paradigm to experimentally probe these issues (for instance, in this study, which reports that 13-15-month-olds show some knowledge of complex what-questions, as in what hit the x?, long before such infants are able to produce this kind of sentences).
[iv] Fodor took the “let’s approach the study of the LoT via analysing linguistic structure” route often, and it is noteworthy that in his famous 1975 book, The Language of Thought, two chapters are devoted to the internal structure of the LoT, one based on the “linguistic evidence” for this internal structure, the other on the “psychological evidence”.
[v] And for another reason to boot: as a way to avoid an equivocation of sorts regarding the number of logical operators available in cognition, thus obscuring important details of the LoT itself. I would have emphasised this point in my comment had the bad, old people at BBS accepted my proposal, but anyway, here’s the gist of it. Quitly-Dunn et al. report a Bayesian study on the number of logical operators the LoT most likely has, which seems to match some evidence regarding the number of operators, from the possible 16 binary connectives from formal logic, plus the unary operator of negation, that are more readily learnable by participants in an experimental task, which turns out to be a small set: conjunction, disjunction, the conditional, and the biconditional, plus negation. This particular set has been “lexicalised” in many of the world’s languages in one way or another, however – that is, these logical operators have turned up as actual words in various languages (I ignore the complication that no words actually behave like the conditional and biconditional connectives of logic, but let that stand) – and therefore the conclusion Quilty-Dunn et al. reach in this case may be the result of conflating an account of lexicalisation – the question of why these operators have been lexicalised instead of others, a topic intensely studied in semantics and pragmatics – with an account of the availability, or entertainability, of logical operators in non-linguistic cognition. There are many mismatches, or misalignments, between linguistic and conceptual representations, one of which precisely involves the fact that not all conceptual differences are expressed in language – that is, not every possible concept is lexicalised. Indeed, some evidence suggests that various unlexicalised concepts, such as the connective NAND from logic or the opposite of the linguistic determiner most (i.e., a determiner with the meaning “less than half”), are perfectly learnable in carefully designed experiments – and, thus, must plausibly be part of the LoT but not of language, a contingency that would appear not to be countenanced by the evidence Quitly-Dunn et al. adduce (some of this work is my own, where I discuss the dissociation between lexicalisation and “learnability” in some detail).
[vi] There is a lot more to say about this literature, but very little that is actually positive, to be honest. A colleague recently pointed out to me that, if nothing else, the hype of ChatGPT demonstrated how little linguistics had influenced general culture; true that, but I think that’s also the case of certain areas of cognitive science.