

The digital computer emerged out of devices that were built during World War II for cracking codes and calculating artillery tables. Almost as soon as the computer came into existence people were thinking about using it for chess and language. Alan Turing developed Turochamp, an algorithm for playing chess in 1948. Though that algorithm was never implemented, chess became a central topic of AI research, so much so that John McCarthy, who coined the phrase, “artificial intelligence,” would eventually write an article entitled “Chess as the Drosophila of AI.” In 1949 Warren Weaver, then with the Rockefeller Foundation, wrote a memo proposing machine translation. The first public demonstration of machine translation took place in 1954 at the IBM head office in New York and involved 60 Russian sentences.
These two lines of research differed on a philosophical level. AI was a full-on assault on human intelligence. Chess was regarded as the apogee of human intelligence. If we could program a computer to play chess at a championship level, we could program a computer to do anything a human can do. That’s what researchers believed. That’s why chess was so important as a domain of research.
The goal of machine translation was more modest: the reliable translation of documents in one natural language (e.g. Russian) into another natural language (e.g. English). The research programs were correspondingly different and wouldn’t merge/collide until the 1970s with the Speech Understanding Project sponsored by ARPA (the Advanced Research Projects Agency of the Defense Department, now simply DARPA, Defense Advanced Research Projects Agency).
However, I do not intend to recount the history of research in these two areas. As I said, my aim is more philosophical. I’m interested in the radically different nature that these two cases present for AI research. To that end I want to begin by discussing the radically different geometric footprints presented by chess and natural language. With that ground under our feet we can go on to more abstract matters.
What’s that, the geometric footprint of chess, or of natural language? Let’s start with chess. While chess is a fairly cerebral game, it is a game played in the physical world using a board and game pieces. The rules of chess can be defined with respect to its geometric footprint:
- There are two players, who alternate moves.
- It is played on an 8 by 8 board.
- Each player has 16 pieces distributed over 6 types.
- The moves of each type are rigidly and unambiguously specified.
The only constraint the players are subject to is the constraint that they obey the rules of the game. Any move that is consistent with the rules is permitted. The basic rules of chess are so simple that computers need not play chess by moving physical pieces around on a board; a purely symbolic notation is entirely adequate.
Now let us consider human language. It has a geometric footprint as well, which is given in language’s relationship to the natural world. The meaning of a good many words is given directly by physical phenomena; much of so-called common-sense knowledge is like this. Apples and oranges are physical things, as are fish, birds, beasts and human beings. We also have such things as the wind and the ocean, and the sun, the moon, and the stars. All of these things have physical extension; most have clear boundaries, but not the wind. What of truth, love, beauty, justice and many other abstract concepts? As such their primary meaning is not specified in physical terms set by the human sensorium. Rather, they are given meaning by various means, including patterns of words and patterns that include formal symbols as well, symbols from mathematics, chemistry, physics, and so forth. Unlike the geometric footprint of chess, which is small, simple, and well-defined, the geometric footprint of language is large, complex, and poorly defined.
And then we have the fact that chess is a well-defined game. Each game has a beginning and an ending, and rules that specify how pieces may be moved in between. Taken as an object of computational analysis, or as an activity to be executed by a computer, chess is well-defined, at least on a basic level.
What about language? How does one play language? What is the objective? Though the philosopher Ludwig Wittgenstein may have talked of language games (Sprachspiel), and we do play games with language, such as Scrabble, crossword puzzles, or The Dozens, a form of verbal combat common in some African-American communities, language is not a game with well-deified rules. When we learn to write we generally learn so-called rules of grammar. By that time, however, we have been speaking for several years and doing so without ever having learned explicit rules. And those rules of grammar, they are not well-defined and, unlike the rules of chess, they do not constitute a finite set. Moreover, language that breaks those rules may still function perfectly well.
We know what a chess program does: It plays games of chess. If we’re going to program a computer to “do” language, what kind of tasks are we going to give it? As I noted in the introduction, the first language task we had computers do was to translate from one language to another. Later on researchers would devise programs to answer questions, generate stories, or summarize text. You might think that, most generally, language is a means of communication. But it is also a tool for thinking and we use it as such without necessarily having any immediate intention of communicating with someone.
My point then is simple, that considered as phenomena for computational investigation, chess and natural language are very different. Chess has a well-specified geometric footprint, language does not. Chess has well-defined rules; language does not. And then we have the fact that, for some time, chess has been associated with intelligence. Thus for decades chess matches were an important form of competition in the Cold War between the United States and the USSR. AI researchers have been interested in chess because they believed that, if can figure out how to program a computer to play an expert game of chess, then we can figure out how to program a computer to perform any cognitive task. Language has not been so regarded. Anyone can speak and write passably well. And, while anyone can learn to play chess, only an elite few play it well enough to merit our attention.
Researchers who identified with the aims of AI weren’t interested in language until the 1970s. Up to that point all of the computational research on language was undertaken by researchers who identified themselves as computational linguists. These were two different intellectual communities, with different meetings, journals, and professional associations.
Chess is a game where there is a strict distinction between the basic rules and what we might call the elaboration, that is, the tactics and strategies governing games play. To play chess at even a quite modest level one must have a repertoire of tactics and strategies that are not specified by the rules but are consistent. with them.
As I have already noted, a game of chess is played on a board of finite size, an eight by 8 eight grid. The moves possible for each piece are specified exactly. Thus: pawns move ahead one or two squares for their initial move, one square thereafter; they capture one square diagonally forward and they cannot move backward. Bishops move any number of squares diagonally in either direction. And so forth for rooks (castles), knights (horse), the king and the queen. The positions of pieces on the board are specified for the opening positions, and so forth for the roughly a dozen rules that define basic game play (there are more rules for competitive play). The upshot is that chess is a two-person game, of perfect information (that is, both players are fully aware of the complete state of play at any moment), and is finite.
Just what does that mean, “finite”? That means that there are only so many possible chess games, and no more. To see this it is helpful to create a sketch of the space of chess games. It takes the form of a tree, like this:
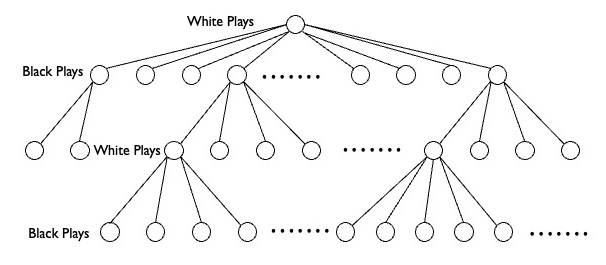
By convention, White plays first and has 24 moves open to them (too many to depict in the illustration): each of eight pawns can move one or two spaces ahead, and either knight has two possible moves. Moving second, Black has the same 24 possible responses to whichever move White makes, chosen from the 24 possibilities open to it. At that point the chess tree is 576 (24^2) branches wide. White then makes their second move, choosing one from however many possibilities are open. The game continues in that manner. At any given point, the player taking the move has only a finite number of choices available to it. The game then continues until either one player wins or a draw is declared (by a convention established in the basic rules).
It follows from this, then, that the chess tree is finite and that there are an estimated 10^120 possible games, a number known as the Shannon number after the mathematician Claude Shannon, who made the initial estimate. As a comparison there are only 10^80 atoms in the observable universe. So, while the number of possible chess games is finite, it is infinite for all reasonable purposes. The chess tree cannot be calculated.
The important point is simply that, as a subject for computational investigation, chess is well-formed and relatively tractable. Language, as we’ll see in a moment, is not. To a first approximation, there are two aspects of playing chess, search and evaluation. Given that one has learned the rules, the strategy and tactics of chess play have to do with searching the tree and evaluating each possible move: How will this move bring me closer to winning, or prevent the other player from winning?
Four roughly 45 years or so researchers made steady progress in developing computational approaches to chess strategy and tactics. Finally, in 1997, IBM’s Deep Blue beat world champion Gary Kasparov in a six-game match. At that point, AI researchers declared chess to be a “solved” problem.
Now, I should say that, in skipping over those four decades of research into computational approaches to strategy and tactics, I’m skipping over most of the story of chess computation. That’s where the action is. What I’ve talked about is just the framework within which that research was conducted. But THAT’s the POINT. As we’ll see shortly, there is no such framework for language.
As a final point, the framework for chess is, from an abstract point of view, the same as the framework for a much simpler game, tic-tac-toe. Tic-tac-toe is interesting and challenging for a six-year old, but trivial for a ten year old. Just as the game space for chess takes the form of a tree, so does the game space for tic-tac-toe. Both games involve two players who alternate moves on a board that is visible to both. But the tic-tac-toe board is only three by three and is played with Xs and Os rather than six different game pieces. There are 255,168 possible games, a large number, but trivial in comparison to chess’s 10^120 possible games.

Computing Language
Let’s return to the beginning, the geometric footprint. Chess has a clear well-defined geometric footprint and that, in turn, leads to a clear well-defined framework – the chess tree – within which to conduct the computational study of chess. Language does not have a clear well-defined geometric footprint. The number and variety of physical objects and phenomena to which words and phrases can be assigned seems unbounded and distinctions are often murky. Moreover language is full of words for abstract concepts, concepts which do not have any direct relationship to the physical world. This alone should tell us that the computational investigation of language has not gone so well as that of chess.
For several decades now the study of language has focused on syntax and that is where most of the early work on machine translation has focused, as Martin Kay has explained in an excellent article from1973, Automatic Translation of Natural Languages. What are the rules that govern sentences? How can we characterize an infinite set of sentences using a finite set of syntactic rules. One aspect of the rules is a finite list of word types: nouns, verbs, adjects, and the like. Then we have a limited, but by no means clear, set of rules that govern how word types can be organized into sentences.
Why is it important to have a finite set of word types? While the vocabulary of a language is finite at any given moment in time, that vocabulary is subject to change, and may well grow over time. If however we can classify every word as being an example of some particular word type, and allowing that some words may function in two or more types, then the actual composition of the vocabulary at any one time doesn’t matter. We can define syntax in terms of word types alone.
To translate a sentence from one language into another you begin by parsing the sentence. As Kay explains:
It is generally agreed that any machine-translation system intended to produce results of high quality must carry out a syntactic analysis of every sentence in the text to be translated. The product of this analysis usually appears as a labeled tree representing the surface or preferably the deep structure of the sentence. Developing a structure of this kind has two important advantages. First, the function that a word or group of words fulfills in a sentence cannot usually be determined simply by examining neighboring words and phrases. It can be determined only by insuring that any function proposed for it is compatible with that proposed for every other word and phrase in the entire sentence. In other words, the most solid basis on which to assess whether a function has been correctly as signed is provided by a structural analysis of the sentence.
For a variety of reasons well-beyond this article, a wide variety of strategies have been developed for parsing, with varying degrees of success. They tend to be subject to the problem of combinatorial explosion, as sentences become longer and more complex, the number of possible parses that must be explored increases, and tends to do so exponentially. That, as much as anything, is what killed early work in machine translation. Well, “killed” is perhaps too strong a word, but it points in the right direction.
And translation is only one of many possible language tasks. It is one thing to translate a document from one language to another. A program that does that will not thereby be able to tell a story, or explain how to use a tool, or even to describe that tool, or negotiate a deal, or any of the many things one can do with language. Computing language is thus an utterly different kind of problem from computing chess.
But it was of no interest to early AI researchers. Chess, now that takes intelligence, but language, not so much. That is an instance of what is known as Moravec’s paradox:
Moravec’s paradox is the observation that, as Hans Moravec wrote in 1988, “it is comparatively easy to make computers exhibit adult level performance on intelligence tests or playing checkers, and difficult or impossible to give them the skills of a one-year-old when it comes to perception and mobility”. This counterintuitive pattern may happen because skills that appear effortless to humans, such as recognizing faces or walking, required millions of years of evolution to develop, while abstract reasoning abilities like mathematics are evolutionarily recent. […] Similarly, Minsky emphasized that the most difficult human skills to reverse engineer are those that are below the level of conscious awareness. […] Steven Pinker wrote in 1994 that “the main lesson of thirty-five years of AI research is that the hard problems are easy and the easy problems are hard.”
Language is one of those skills that function “below the level of conscious awareness,” while chess is not. The rules of chess, unlike those of syntax, are explicit, and playing chess requires conscious, deliberate effort, where speech is often all but effortless.
Leaving most work in computational linguistics behind, however, there is one milestone worth mentioning here. In 2011, fourteen years after Deep Blue beat Kasparov, IBM’s Watson defeated Brad Rutter and Ken Jennings on Jeopardy! Watson was a question-answering system in reverse. Rather than answering a question presented to it, it had to come up with a question appropriate to an answer it was supplied with. This is a natural language task, though a very specialized and somewhat peculiar one. For what it’s worth, I suspect that, if one were to add up the total research hours that led to Watson, both directly and indirectly (here I’m thinking of the natural language research that took place prior to the beginning of the Watson project), I suspect that it would be considerably larger than the total direct and indirect research involved in Deep Blue’s chess victory.
Where are we now?
That’s not at all clear. The large-language models (LLMs) that currently power chatbots such as ChatGPT, Claude, and Gemini are much more impressive and versatile than any of the natural language systems developed in the previous century. But they are also based on a much different kind of computing technology. The older systems were based on what I will, somewhat tendentiously, call transcendent coding, though I don’t mean transcendent in its ordinary sense: “beyond or above the range of normal or merely physical human experience.” Rather, they have been coded from a point outside the system being programmed. At least in principle the programmer, or programmers, can observe the system from the outside, that is, from a point of view that transcends the system itself. They can observe all the parts and their relations to one another. That’s what I mean by transcendent. Almost all computer programs are transcendent in this ultimately trivial sense.
Chess can be fully specified externally. That’s what allowed researchers and programmers to create Deep Blue. We do not know how to specify language externally.
The situation is quite different for machine-learning systems, which are the basis for LLMs. LLMs are created with a particular kind of system known as a transformer (the name is not important to us). The transformer “chews” its way through a large corpus of written texts, effectively, the entire internet, and in that process constructs a (statistical) model of those texts. That model is then used to respond to natural language prompts from users. The transformer program is transcendent just like most other computer programs. But the model it creates, the LLM, that is not transcendent. We do not know how those models work; we cannot specify their operations externally.
And by “we” I mean not only you and me, but the researchers and programmers who created the transformers. They know how the transformer program works, but not the LLM the program creates. LLMs are computational systems, but they were not created by a process in which a human transcends the program. They have not been specified externally. The operations of LLMs are deeply mysterious. When people talk about superintelligence they are, in effect, talking about an artificial system that in some sense transcends us.
* * * * *
The fact is, by the time Deep Blue beat Kasparov, it was just another AI program specialized to operate in a particular domain. Deep Blue may have been aces at chess, but it couldn’t do anything also, including tic-tac-toe or tell a simple story. Chess was no longer the “Open sesame” to human intelligence.
In 1997 Deep Blue was a large and highly specialized system, though it was rather modest in comparison to other supercomputers. Now I could run Stockfish (a standard chess engine) on my MacBook Air, which is a rather modest machine, and that system could be any human chess player in the world. For that matter, Claude tells me that Stockfish on a smartphone beats magnus Carlsen consistently. In contrast, the LLMs powering chatbots run on massive server farms and consume enormous amounts of power. While these systems are enormously impressive – any one of them “knows” more than any individual human, it is by no means obvious that any of them have “solved” human intelligence in the say that Deep Blue, or Stockfish on a smartphone, has “solved” chess.

Note: Whereas Claude drafted most of my previous article for 3 Quarks Daily, “Of Grammar and Truth: Language Models and Norms, Truth and the World,” I drafted and edited this article. But I used Claude for research. ChatGPT 5.2 created the images under my direction.
Enjoying the content on 3QD? Help keep us going by donating now.