
by Jochen Szangolies
There is a widespread feeling that the introduction of the transformer, the technology at the heart of Large Language Models (LLMs) like OpenAI’s various GPT-instances, Meta’s LLaMA or Google’s Gemini, will have a revolutionary impact on our lives not seen since the introduction of the World Wide Web. Transformers may change the way we work (and the kind of work we do), create, and even interact with one another—with each of these coming with visions ranging from the utopian to the apocalyptic.
On the one hand, we might soon outsource large swaths of boring, routine tasks—summarizing large, dry technical documents, writing and checking code for routine tasks. On the other, we might find ourselves out of a job altogether, particularly if that job is mainly focused on text production. Image creation engines allow instantaneous production of increasingly high quality illustrations from a simple description, but plagiarize and threaten the livelihood of artists, designers, and illustrators. Routine interpersonal tasks, such as making appointments or booking travel, might be assigned to virtual assistants, while human interaction gets lost in a mire of unhelpful service chatbots, fake online accounts, and manufactured stories and images.
But besides their social impact, LLMs also represent a unique development that make them highly interesting from a philosophical point of view: for the first time, we have a technology capable of reproducing many feats usually linked to human mental capacities—text production at near-human level, the creation of images or pieces of music, even logical and mathematical reasoning to a certain extent. However, so far, LLMs have mainly served as objects of philosophical inquiry, most notable along the lines of ‘Are they sentient?’ (I don’t think so) and ‘Will they kill us all?’. Here, I want to explore whether, besides being the object of philosophical questions, they also might be able to supply—or suggest—some answers: whether philosophers could use LLMs to elucidate their own field of study.
LLMs are, to many of their uses, what a plane is to flying: the plane achieves the same end as the bird, but by different means. Hence, it provides a testbed for certain assumptions about flight, perhaps bearing them out or refuting them by example. After the first plane took off, the discussion of whether heavier-than-air flying machines are possible was decisively concluded. Are there areas of philosophical inquiry where LLMs can offer similar demonstrative power? In the sequel, after briefly introducing some aspects of their inner workings, I propose that LLMs can offer us new insights at least in three areas—the philosophy of language, the evaluation of philosophical thought experiments, and perhaps most interestingly, the identification of implicit, systemic bias.
Talking Without Speaking
The breakthrough capability of LLMs is their ability to reproduce the human ability to produce sensible-seeming text, often to a degree of verisimilitude that makes their output hard to distinguish from human language production. Many predict that what gaps remain will also soon be closed, leaving us with a non-human entity with human-equivalent language capabilities.
Language, in turn, has been a central object of philosophical attention ever since the ‘linguistic turn’ in the beginning of the 20th century. What can the emergence of a second language-producing entity tell us here?
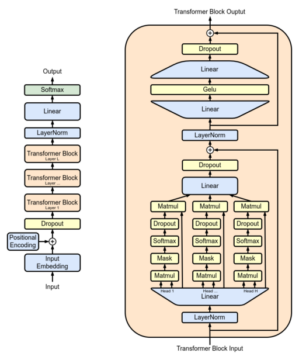
To get a start on this issue, we first need to take a brief look at how LLMs actually produce language. I won’t go into any great detail here—if you want a great visual overview, I suggest you check out this video and its follow-up by the channel 3Blue1Brown. For our purposes, a brief summary will suffice.
LLMs work by means of encoding elements of a fixed vocabulary into representations given as a list of numbers (a vector). This ‘vocabulary’ generally doesn’t consist of words, as such, but of tokens, which may be subunits of words, or even punctuation marks—but we won’t worry much about this distinction here. So: every word is encoded into a vector with many components (that is, it has a high dimension). This embedding has the special property that similar words will lie ‘close’ to each other, which is achieved through training by noting that similar words tend to stand in similar relations to other words: the maxim is that “you shall know a word by the company it keeps”, coined by English linguist J. R. Firth in the 1950s.
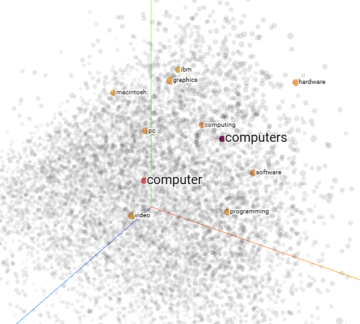
Having words represented by vectors has the advantage of being able to perform mathematical operations on them. For one, we can associate a degree of similarity to certain words, simply by comparing how well they are aligned. To get a feel for how this sort of thing works, it might be useful to play around with the embedding projector, which lets you enter words and output the set of words closest to it, represented in the form of a point cloud projected down to three dimensions.
More interestingly, we can combine certain meanings by algebraic operations—adding or subtracting them from one another. The classic example here is ‘King’ – ‘Man’ = ‘Queen’ – ‘Woman’, such that one can arrive at (the vector representation of) ‘Queen’ by subtracting ‘Man’ from ‘King’, then adding ‘Woman’. You can play around with some word algebra here, using text drawn from different sources, such as Wikipedia.
But more than the mere word meaning is encoded in a vectorial representation. There is a certain leeway to this encoding—meaning that we can vary each vector somewhat, without changing its overall meaning. The reason for this is that the points representing a given word are typically very isolated, since the representation space is very high-dimensional. We can use this to store more information in a word vector.
One additional important bit of information is a word’s location in a sentence. The meaning of a sentence isn’t given merely by the meaning of the words it contains; word location matters. Thus, to every word vector, we can add a locational embedding in the form of another vector, without changing the ‘base meaning’ of the word.
But the real trick that supplies much of the magic behind a LLM’s operation is to also encode context into its representations. This is needed, for instance, to disambiguate between homonymes—consider the word fluke, which may mean both a stroke of luck and a whale’s fin, for example. Merely adding locational information won’t suffice to disambiguate between these options; thus, something more is needed.
That ‘something more’ is essentially supplied by the attention-mechanism. I won’t try and go into the details of this mechanism here (but see again this video by 3Blue1Brown), other than to note that it is a way of associating words relevant to one another in such a way as to update the representation of a given word to remove as much ambiguity as possible. Essentially, each word issues a kind of ‘self-description’ (a key), as well as a kind of ‘help wanted’-ad (a query), such that words whose description matches to that query are used to further update the representation. That way, generic terms get gradually loaded up with increasing amounts of contextual information—a nondescript ‘castle’ might become ‘castle, in France, former royal residence, commissioned by Louis XIV’, and so on. All of these further specifications are folded into the representation of the original ‘castle’ by means of translating the vector along certain directions in the high-dimensional space that correspond to additional bits of semantic information.
It is now these ‘context-laden’ representations a LLM uses to produce novel bits of text. (By the way, even though I’m talking mostly about text-generating models here, similar remarks hold for the production of audio and video, with tokens corresponding to relevant chunks of image or lengths of audio.) The text up to a certain point (as generally encoded within the representation of the final token) is used to generate a probability distributions of possible successor words, from which one is sampled. Then, the procedure is repeated, adding word by word to its output.
This is, at least in my experience, strikingly different to human text production. When I try to put my thoughts into words, I try out phrasings, revise, rewrite, start afresh, edit, reorder, and so on—both internally and on the page. Hence, as with birds or planes flying, we seem to have two different means of generating a comparable result. What does this tell us about the facility thus replicated?
Language In The Light Of LLMs
Noam Chomsky famously proposed that language acquisition is only possible since we are all endowed with a certain ‘universal grammar’, a kind of minimal structure of language, from birth. There is no such universal grammar in LLMs, yet they seem capable of acquiring language. Does this allow us to conclude that Chomsky must have been wrong?
That this is so has indeed been proposed by UC Berkeley researcher Steven T. Piantadosi. However, we should be careful to not be too quick, here. One of Chomsky’s key points was the poverty of the stimulus—the amount of training data, so to speak, each child is exposed to is, ultimately, quite small. On the other hand, modern LLMs are trained on large datasets representing a significant fraction of the totality of texts in existence—something no human being could ever ingest across several lifetimes.
Furthermore, there may be debate on how ‘human-like’ LLM language output really is. Famously, a main issue of these systems is the prevalence of hallucinations—assertions presented as fact without any factual basis. In short, sometimes, they make things up. Moreover, this seems to be an innate limitation of LLMs. Humans, in contrast, sometimes say things that are wrong, whether by lie or mistake, but there is typically a clear distinction between factual and erroneous content; to a model like ChatGPT, it’s all the same. So there might be an argument here that the production of language works saliently different, making the comparison less clear.
But there are other philosophically relevant aspects of large language models. In the early 20th century, ideal language philosophy sought to find a perfectly unambiguous mode of expression that would show most philosophical problems to be ‘pseudo-problems’ merely produced by inexact expressions of ordinary language, and thus, not solved, but rather ‘dissolved’. The ideal language was to take the form of logically precise formulations leaving no room for interpretation, with anything that can not be thus formulated being revealed as mere nonsense.

Such an ideal language would then allow for an entirely mechanized reasoning, with the truth or falsity of a given proposition established by computation, fulfilling Leibniz’ dream of the ‘Calculemus!’ (‘Let us calculate!’).
Large language models, to the extent that they do reason at all, certainly do implement a kind of ‘mechanized reasoning’. Moreover, their representations, though humanly unreadable, are capable of ever-increasing accuracy, progressively shedding all ambiguity—confining any concept to an ever-smaller part of the embedding space. Ultimately, one might imagine that one could arrive at a perfectly disambiguated concept that fully captures the reality behind it, without any room for the vagaries of natural language.
Their representations then allow for an incorporation of both Fregean ‘Sinn’ (‘sense’) and ‘Bedeutung’ (‘reference’). For instance, the terms ‘morning star’ and ‘evening star’ have the same reference—the planet venus—but differ in their sense, the context in which they stand. In an LLM, this context will inform the representation, becoming ‘baked in’ as a part of the concept which might be considered a distinction in reference between ‘venus-as-evening-star’ or ‘venus-as-morning-star’.
The problem is, however, that this process does not have a well-defined end point. Imagine an entire book written like a historical text, describing the marriage of some past king on its first few pages, but then, on its very last page, ending with the sentence ‘All of this happened in the fictional land of Ur.’ Whatever ‘knowledge’ the LLM represents about that king must now include reference to his being fictional—hence, the process of disambiguation can never really stop. There thus sneaks a sort of approximation of Derrida’s concept of ‘différance’ into the process of this disambiguation: the meaning of any representation always differs from the ‘true’ concept, and its full explication is continually deferred to possible elucidation by interaction with later representations. As this concept was part of Derrida’s critique of the logocentrism of mechanized reasoning, there may be a hint of irony here.
Zombies In The Chinese Room
Changing gears, we might look to LLMs as proxies for bringing philosophical thought experiments closer to reality. An example of this is John Searle’s famous Chinese Room, which imagines him sat in a room closed from the outside save for the means of receiving and issuing snippets of paper. On these, Chinese characters are written. Searle has access to a book of rules, which instruct him in the manipulation of these characters, producing appropriate ‘responses’. From the outside, it seems as if the room is engaged in a meaningful Chinese conversation; from the inside, Searle has no knowledge of its topic.
The innovations LLMs bring to this setting is that now, the rulebook actually exists—it’s in the weights of the transformer model. Searle could, in principle, carry out all of the operations of the LLM by hand—finding a vector encoding of a given Chinese character, updating it according to the representations of other characters, finally producing a response one character at a time. He would, as per the original thought experiment, himself remain totally ignorant of the character’s meanings: they are simply not a factor in the process.
It is certainly plausible that the evaluation of transformer rules won’t enable Searle to understand language. However, even in the original formulation, few objected to this conclusion. Rather, the most common reply by far was the so-called systems response, according to which it isn’t Searle, but the entire system he is part of, that possesses an understanding of Chinese. Do LLMs shed new light on this issue?
I think here the answer might well be yes, with a few caveats. The argument I outlined in this earlier column aims at establishing that, despite their apparent linguistic prowess, LLMs have no idea what they’re talking about: the meaning of the tokens they manipulate remain opaque to them. If this is true, then there seems little grounds on which one might locate any understanding within a system instantiating such a model.
However, this still falls short of the argument’s original goal. Searle aimed at demonstrating that no algorithmic means to produce genuine understanding could exist. If the above is right, we only know that the particular way in which LLMs produce language fails to do so. This does represent a kind of progress, in that it demonstrates that no immediate link between behavioral competence and the understanding that underlies this competence in the human case exists, but it leaves open the larger question of whether there could be some algorithmic means of providing true understanding.
That LLMs are our behavioral (near-) equals conjures up a comparison with another famous philosophical thought experiment, namely, David Chalmers’ zombie argument. Chalmers invites us to imagine a being that is physically identical to us, thus behaving in all the ways we do, yet lacking any sort of subjective inner experience. If such a being is possible, then the physical facts alone don’t fix the facts about the mind, and thus, something non-physical is needed to explain subjective experience.
One might imagine a ‘zombie’ as realized by a robot running a transformer model, thus showing at least linguistic capabilities equal to us. But this again falls short of the original aim: such a zombie would not be physically identical to us, but merely in terms of behavior, and thus, only refute the considerably stronger claim that phenomenological facts are fixed by behavioral facts. But since the downfall of behaviorism in the 1960s, few if any have held to such a thesis.
Hence, it seems that while LLMs may offer a new perspective on philosophical arguments, they don’t lend themselves to offering up any fundamentally new conclusions.
Systemic Inequality As Data Bias
Large language models ingest prodigious amounts of text, and uncover the relations between concepts as that corpus contains them. A final potential philosophical application, then, is to use them—or more precisely, the way they represent that data—to probe the hidden connections present in these texts, and explore how they reflect hidden biases in society. To this end, let’s start with an experiment.
First, open up the semantic calculator linked to already above. Then, enter into the boxes the words ‘man’, ‘doctor’, and ‘woman’—essentially posing the question of what is to ‘woman’ as ‘doctor’ is to ‘man’. Choose your favorite corpus of texts. What is the result?
If I use the English Wikipedia corpus, the top answer is ‘physician’. However, the second best fit will be ‘nurse’. Using the British National Corpus, ‘nurse’ is the top hit. Running the experiment in reverse—‘woman’ is to ‘nurse’ as ‘man’ is to…?—the English Gigaword corpus similarly spits out ‘doctor’.
What does this mean? Well, the difference between ‘man’ and ‘doctor’ could be something like ‘professional in the medical sector’; that this turns out to be ‘nurse’ when combined with ‘woman’ then speaks to an inherent bias in this corpus. The finding is robust: applying the relation between ‘man’ and ‘woman’ to ‘doctor’, the British National Corpus again yields ‘nurse’.
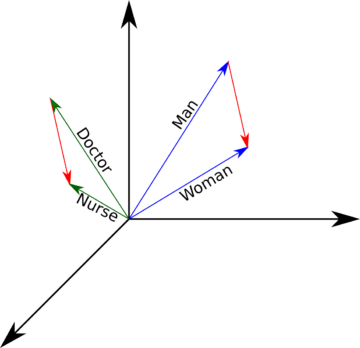
This is then a robust experimental check for the idea that bias does not necessarily just exist at the individual level, but pervades the artifacts of society, namely, texts in this case. The concept of ‘woman’ is more closely associated to that of ‘nurse’ than that of ‘doctor’, despite the fact that members of either sex can be doctors as well as nurses.
So far, this application has focused solely on the representation used by LLMs at the ‘zeroth’ level, where words are straightforwardly encoded into vectors. What would be interesting is to see how these representations are influenced by context. What happens to the representation of the concept of, e. g., ‘gender’ over the course of a text?
An analysis of this shift in meaning might yield insights not readily available at the surface level of the text. This has the potential of being an intriguing tool to study systemic bias, which is especially important in a time where the very existence of such a bias is sometimes called into question. It also could furnish a basis for effective measures to combat such bias: what would we have to change in a corpus of texts, so that this bias no longer persists? If such an analysis is possible, this has the potential of putting interventions on this level—which, today, are too often haphazard, if well-intentioned—on a firm evidential basis.
In summary, there are interesting opportunities for philosophers willing to add LLMs to their toolkit, whether as a proxy of studying language by adding a second data point to the set of language-producing entities, as a new character in the ever-expanding roster of philosophical thought experiments, or as a technology to directly test the inherent relations between concepts as they are present in some corpus of texts, and thus, uncover possible systemic issues.