
Oliver Whang in The New York Times:
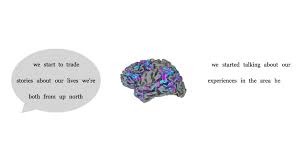 The study centered on three participants, who came to Dr. Huth’s lab for 16 hours over several days to listen to “The Moth” and other narrative podcasts. As they listened, an fMRI scanner recorded the blood oxygenation levels in parts of their brains. The researchers then used a large language model to match patterns in the brain activity to the words and phrases that the participants had heard.
The study centered on three participants, who came to Dr. Huth’s lab for 16 hours over several days to listen to “The Moth” and other narrative podcasts. As they listened, an fMRI scanner recorded the blood oxygenation levels in parts of their brains. The researchers then used a large language model to match patterns in the brain activity to the words and phrases that the participants had heard.
Large language models like OpenAI’s GPT-4 and Google’s Bard are trained on vast amounts of writing to predict the next word in a sentence or phrase. In the process, the models create maps indicating how words relate to one another. A few years ago, Dr. Huth noticed that particular pieces of these maps — so-called context embeddings, which capture the semantic features, or meanings, of phrases — could be used to predict how the brain lights up in response to language. In a basic sense, said Shinji Nishimoto, a neuroscientist at Osaka University who was not involved in the research, “brain activity is a kind of encrypted signal, and language models provide ways to decipher it.”
In their study, Dr. Huth and his colleagues effectively reversed the process, using another A.I. to translate the participant’s fMRI images into words and phrases. The researchers tested the decoder by having the participants listen to new recordings, then seeing how closely the translation matched the actual transcript.
More here.