
Marco Ramponi at Assembly AI:
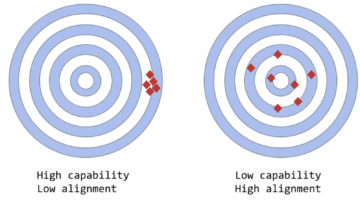 The creators have used a combination of both Supervised Learning and Reinforcement Learning to fine-tune ChatGPT, but it is the Reinforcement Learning component specifically that makes ChatGPT unique. The creators use a particular technique called Reinforcement Learning from Human Feedback (RLHF), which uses human feedback in the training loop to minimize harmful, untruthful, and/or biased outputs.
The creators have used a combination of both Supervised Learning and Reinforcement Learning to fine-tune ChatGPT, but it is the Reinforcement Learning component specifically that makes ChatGPT unique. The creators use a particular technique called Reinforcement Learning from Human Feedback (RLHF), which uses human feedback in the training loop to minimize harmful, untruthful, and/or biased outputs.
We are going to examine GPT-3’s limitations and how they stem from its training process, before learning how RLHF works and understand how ChatGPT uses RLHF to overcome these issues. We will conclude by looking at some of the limitations of this methodology.
More here.