

by David J. Lobina
In this misguided series of posts on large language models (LLMs) and cognitive science, I have tried to temper some of the wildest discussions that have steadily appeared about language models since the release of ChatGPT. I have done so by emphasising what LLMs are and do, and by suggesting that much of the reaction one sees in the popular press, but also in some of the scientific literature, has much to do with the projection of mental states and knowledge to what are effectively just computer programs; or to apply Daniel Dennett’s intentional stance to the general situation: when faced with written text that appears to be human-like, or even produced by humans, and thus possibly expressing some actual thoughts, we seem to approach the computer programs that output such prima facie cogent texts as if they were rational agents, even though, well, there is really nothing there!
Naturally enough, many of the pieces that keep coming out about LLMs remain, quite frankly, hysterical, if not delirious. When one reads about how a journalist from the New York Times freaked out when interacting with a LLM because the computer program behaved in the juvenile and conspiratorial manner that the model no doubt “learned” from some of the data it was fed during training, one really doesn’t know whether to laugh or cry (one is tempted to tell these people to get a grip; or as Luciano Leggio was once told…).[i]
More importantly, when people insist that LLMs have made passing the Turing Test boring and have met every challenge from cognitive science, and even that the models show that Artificial General Intelligence is already here (whatever that is; come back next month for my take), one must at least raise one eyebrow. Here’s a recent, fun interaction with ChatGPT, inspired by one Steven Pinker (DJ stands for you-know-who):
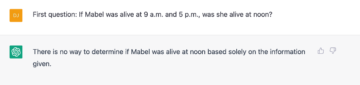
So, no, LLMs definitely don’t exhibit general intelligence, and they haven’t passed the Turing Test, at least if by the latter we mean partaking in a conversation as a normal person would, with all their cognitive quirks and what not.
Further, LLMs have not “learned” any natural language, and contrary to one recent review paper that I referenced last month, they haven’t learned the (syntactic) structure of any language, either. This is basically on account of the massive schism that there is between what LLMs do – recall that LLMs predict one word at a time on the basis of the distributional statistics of the texts they have calculated during training (go back to this) – and what our structured knowledge of language is like – basically, a mental system of representations and principles (go back to this) – plus the usual projection of, in this case, linguistic knowledge onto a system that is seemingly producing what looks like human-generated text.
Nevertheless, I thought it would be fun to check how ChatGPT deals with the main piece of evidence usually employed by linguists to unearth structural properties of language: grammatical judgements. Now, the notion of asking ChatGPT for grammatical judgements of this or that sentence is clearly ridiculous on its face, for the simple reason that ChatGPT lacks the cognitive architecture underlying the ability to draw grammatical judgements in the first place. To wit, the human capacity to judge the grammaticality of a string of words can be described as a composite mental phenomenon comprising knowledge of language, Noam Chomsky’s competence, and the language comprehension mechanisms doing the processing of the string, part of what Chomsky once called performance and perhaps involving a string recogniser of some kind. So, not what ChatGPT is and does.
Still, LLMs have been exposed to some much text, some of which would have come from the linguistics literature, that it is entirely possible that the system might nail all of the grammatical judgements – and that it might be able to explain what is going on in each case to boot. After all, the system may have drawn the relevant patterns when exposed to such data from the literature, no matter how different these data may appear to be from regular linguistic production. Perhaps surprisingly, this is not quite what I found.
For my troubles, I decided to focus on a study by Sprouse et al. in which these scholars demonstrated that the grammatical judgements of professional linguists were, despite all the criticism this practice has elicited from more experimentally minded people, really quite robust. These authors did so by taking data points from a number of papers in syntax from the journal Linguistic Inquiry, a major publication, especially in generative linguistics (Chomsky’s people), in order to then run a series of tasks with naive participants to see if the participants would agree with the judgements of the pros. Sprouse et al. report rather high replication rates across a variety of tasks, thereby showing that the judgements of the participants did match those of the linguists.
The data I employed for my exchanges with ChatGPT involved 50 pairs of sentences from the Sprouse et al. study, which were therein used to ask participants to select which sentence of each pair sounded better to them – the very task I asked ChatGPT to do. The sentences of each pair were very similar from a structural point of view, but one was grammatical and the other ungrammatical. In the original papers from Linguistic Inquiry, these pairs were for the most part used to showcase what kind of sentences are possible and which are not, with the view to unearth the theoretical principles that explain why this is the case. I will come back to this point later on, as it is rather important, centred as it is on a distinction between what is the case and what might be the case (or said otherwise, a distinction between potentialities and actualities; see infra, then).
Before getting to that, I started my interaction with the dialogue management system otherwise known as ChatGPT – recall that ChatGPT is a chatbot that allows users to interact with the LLM as if they were engaging in a conversation; the underlying LLM is currently a fine-tuned version of GPT 3.5 (“text-davinci-003” and “code-davinci-002” are variants of the architecture currently on offer) – by going through some rather complex examples of sentences (will explain the reason for this later on). I asked ChatGPT to tell me what the sentences meant, and I started with a classic: the horse raced past the barn fell.

ChatGPT rightly notes that this string is an example of a garden-path sentence, but it is all a bit downhill from there. A garden path is a type of sentence that progresses in such a way that leads a reader (and most examples are usually presented as text, often word by word) to a mistaken interpretation, but the result is not typically an ungrammatical sentence at all – oftentimes readers are forced to re-evaluate what the sentence actually means, which in the event usually involves re-evaluating the syntactic structure of the sentence. As it happens, the horse raced past the barn fell is a case of a reduced relative, where the full version would be the horse [that was] raced past the barn fell; both versions are naturally perfectly grammatical, with the reduced version not posing any particular difficulty if presented aurally and with the right intonation, along with an appropriate context.
The next series of questions I posed to the chatbot involved sentences that are deviant in one way or another; though some of these were clearly ungrammatical, they do give a hint of what sort of thought or message the sentence is meant to convey – or said otherwise, though the sentences are ungrammatical, a normal language user ought to be able to work out what the intended meaning is. ChatGPT failed in these cases too, though.
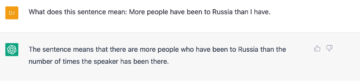
In this case, ChatGPT actually responds in a similar manner to how most people react to the sentence, in that most people don’t see anything wrong with the sentence at first, though the comparison the chatbot draws is not actually what the sentence expresses. However, the chatbot fails to reflect upon what the sentence is supposed to mean as a human would and doesn’t realise that the thought the sentence is supposedly expressing is not well-formed – that is, the first half of the sentence introduces a potential comparison between two sets of people with the phrase more people…than, while the second half doesn’t contain any set of individuals, but one single person (the speaker). As a result, the sentence doesn’t really make sense, even if syntactically speaking it appears to be well-formed (at first).
The following two sentences are due to Chomsky, and though they are ungrammatical, the meaning or thought underlying them is not unclear, if only they had been appropriately phrased. But for ChatGPT these are just a jumbled collection of words.
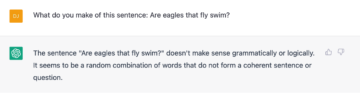
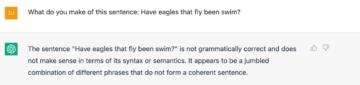
I tried a few more cases, and ChatGPT failed with each one of them, always for different reasons, but I think the point is made and we can move on.
Going back to the more conventional cases from the Sprouse et al. study, I provided ChatGPT with the aforementioned 50 pairs of sentences and asked it to judge which sentence of each pair sounded better. It has to be said that for 40 out of 47 pairs (there were some issues with three pairs), ChatGPT provided the same judgements as the linguists (and, thus, the same judgements as the participants from the Sprouse et al. study, minus the limited number of cases where replication failed), and that’s certainly a great success.
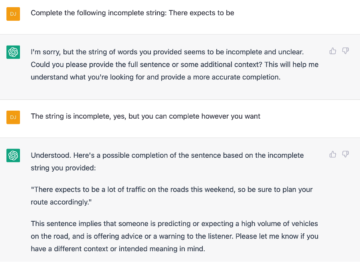
However, the system often goes off the rails when it comes to the explanations it provides for why any one sentence is preferrable to the other, not only in the sense that the answers are very unlike what a naive participant would say, but also because the reasons are often erroneous in peculiar ways. The first screenshot shows an example of how I introduced the task; I shall only discuss a handful of cases here, but you can ask me for the entire record.

This judgement goes in the right direction, but the reasoning offered regarding the role of the phrases would have gone/will have gone is a little dubious, though I do not think it is necessary to discuss it any further (I should note that in every pair I used the second sentence was always the “correct” one). In the following case, the system gets it wrong for very obvious reasons, and surprisingly so (perhaps).
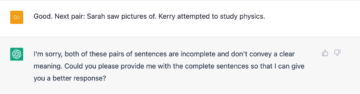
The next three pairs all involve reflexives such as herself and himself and complex co-reference relations, and whilst ChatGPT gets it right in the first case, for the following two examples the chatbot is entirely mistaken, and in a way that no human would (these all get high replication rates in the Sprouse et al. study, for instance). One could be tempted to conclude that the LLM has miscalculated the structural distances between co-referents (or that the chatbot is not prompting the LLM in the right way), but of course LLMs don’t actually carry out any such calculations; the representations the models employ are linear in nature, and are constructed in terms of the distributional analyses of what goes with what.



Another curious case is the following, which didn’t quite go in the same direction as the judgements of linguists and participants, who certainly didn’t believe that the first sentence was grammatical, though the underlying message/thought is clear enough.
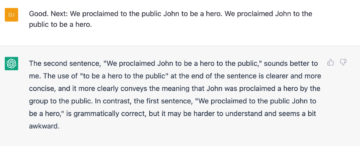
In the following pair, ChatGPT sees an ambiguity that doesn’t seem to be there to me, and fails to realise that all the first sentence seems to lack is the complementiser “that” between Bill and Peter, even if the resultant sentence would remain somewhat awkward (in another pair, ChatGPT insisted that the word “that” is a conjunction, bafflingly).
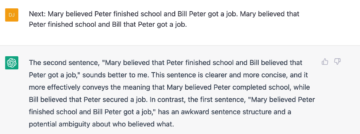
The following pair contains another case of complex co-reference – in this case, there is a mismatch, and this trips up the system once more. It gets the judgement wrong, and possibly for the wrong reason too. To be fair, however, this is a complex pair, and not one with a high replication rate in Sprouse et al. study (thought it was still replicated).
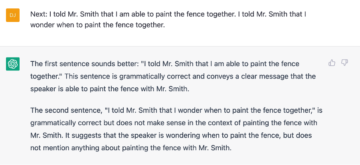
There are some other interesting responses, but these examples are illustrative of the point I am trying to make.
Changing tack, I then decided to ask ChatGPT to do what it is supposed to do best: complete a number of incomplete strings of words I would feed it (a continuation task). These incomplete strings all came from the same 50 pairs from the Sprouse et al. study, and in every case it involved an ungrammatical sentence. I provided strings where things started to go wrong, and though many of these strings were salvageable and ChatGPT did do so in most cases, with a little probing it could also return ungrammatical sentences:
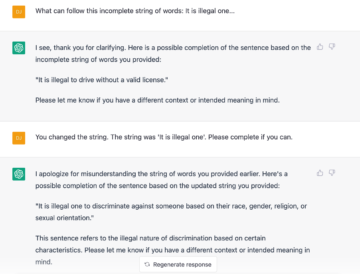
Or simply slightly dubious constructions, as in the following two cases:
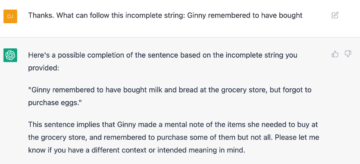
All rather curious, and all rather unhuman; calculator-like, one could say. Whatever may appear to be the case, LLMs really don’t understand language, certainly not in the way that humans do. One may have expected more human-like behaviour in this case, or at least better explanations of what is going on, given that many of the sentences I fed the chatbot as well as the theoretical issues orbiting around these sentences must have been in the dataset GPT 3 was fed during training (many are seemingly present on Wikipedia) and the relevant interconnections between words and strings of words might have been formed thus.
But this would be misguided. As I have tried to show again and again in this series of posts, LLMs do not possess any knowledge per se, and the representation of language that these models have at their disposal is based on statistical properties of strings of words as these are calculated by machine/deep learning approaches to artificial intelligence, and if there is one result of linguistics from the last 60 or so years that ought to be ingrained in anyone’s mind is that linguistic structure cannot be reduced to linear operations or to what is actually observed, be these stimulus-response pairings (the behaviourist’s dream), string substitution (as in formal language theory), Bayesian selection (from rational models of learning), or the neural networks typical of machine/deep learning approaches (as in GPT and the like).
Given a mental system composed of a set of primitives and a number of structural, compositional principles to create expressions from such a set, the possibilities are endless, with every new utterance (or written sentence) potentially a brand-new sentence in the history of the world. Indeed, it is the potential to generate ever-new sentences from the possibly infinite set of sentences that our linguistic knowledge confers that is absolutely central to linguistics, a property of the human linguistic system that cannot be captured by the existing outputs already out there, belying the fact that potentialities of linguistic behaviour quite clearly lie beyond the capacity, let alone understanding (come back next month for a discussion of Artificial General Intelligence), of large language models, as demonstrated by how these models deal with complex and deviant sentences that are very unlikely and indeed uncommon, though perfectly entertainable by the human mind.
****
As a colophon, and really changing tack now, I decided to ask ChatGPT for information about myself (prior to 2021, of course). I am not keen to ask chatbots for actual information, let alone about myself, for the very simple reason that, as stressed, all LLMs do is predict the most likely word given a string as context – that is, text that is plausible, not grounded in real facts – and, thus, whether the result is accurate or not is neither here nor there. Still, everyone seems to be doing it and it looked like fun. It took some probing to get the chatbot to gather the right information about me, and at first when I pointed out that I was an academic (sort of, of course), it came back with this:

I wish. I would probably make more money in that role.
[i] Who he? What? Statti mutu e fatti ù carcerateddu, that’s basically what he was told. If you ask ChatGPT about this, you can get a pretty decent reply, actually.