
by Jochen Szangolies

Turn your head to the left, and make a conscious inventory of what you’re seeing. In my case, I see a radiator upon which a tin can painted with an image of Santa Claus is perched; above that, a window, whose white frame delimits a slate gray sky and the very topmost potion of the roof of the neighboring building, brownish tiles punctuated by gray smokestacks and sheet-metal covered dormers lined by rain gutters.
Now turn your head to the right: the printer sitting on the smaller projection of my ‘L’-shaped, black desk; behind it, a brass floor lamp with an off-white lampshade; a black rocking chair; and then, black and white bookshelves in need of tidying up.
If you followed along so far, the above did two things: first, it made you execute certain movements; second, it gave you an impression of the room where I’m writing this. You probably find nothing extraordinary in this—yet, it raises a profound question: how can words, mere marks on paper (or ordered dots of light on a screen), have the power to make you do things (like turning your head), or transport ideas (like how the sky outside my window looks as I’m writing this)?
Clearly, part of the reason is that words have meanings: they’re symbols which, either alone or in conjunction with others, refer to things in the world, or to actions to be carried out, or states of affairs, or what have you. Words possess what in philosophy is often called intentionality, after Franz Brentano, who applied this concept to the study of the mind in 1874. The word comes from Latin tendere, to stretch, and illustrates the idea that a symbol somehow ‘stretches out’ into the world, connecting with its referent. (Note that intentionality, conceived of in this way, should not be confused with ‘intentional action’, as in action directed at a certain goal or carried out with a certain aim.)
It’s clear that a word—or any symbol in general—does not simply refer to its referent in an intrinsic way: an American reading the word ‘gift’ printed on a box would have a different attitude towards opening it than a German (‘Gift’ is German for ‘poison’). Hence, what a word, or a message, means is due to the interpretation of its recipient; thus, we must look for intentionality ultimately within the mind that does the interpreting.
Indeed, Brentano went so far as to consider intentionality the defining property of the mental, arguing that ‘no physical phenomenon exhibits anything like it’. If that is indeed the case, we have here a sharp dividing line, something that precisely delineates physical and mental phenomena—and moreover, an insurmountable obstacle to any materialist understanding of the mind.
Mechanical Meaning
At first blush, though, the riddle does not seem all that perplexing: so, my words, the symbols I’ve transmitted to you, made you perform a certain action—turn your head. Big deal; in today’s world, we’re everywhere surrounded with machines—physical devices—capable of turning commands into actions: whenever you type an instruction into your computer, whenever you begin a sentence with ‘Alexa…’, or even whenever you just flick a switch to turn on the light, you issue a command to a mechanism which is promptly translated into action.
Let’s take a closer look at this. Suppose you have a device, a universal constructor, capable of reading a blueprint and constructing whatever it describes, resources permitting (Fig. 2).
At first blush, this would seem to be a textbook example of symbol-interpretation: the blueprint is the symbol given to the constructor, which interprets it, and then constructs the object it represents. From this, we might conclude that to the constructor, the blueprint means the object it has constructed. But this would be premature.
To see why, consider the following setting: you’re placed in a labyrinth, tasked with finding your way out. Thankfully, you soon realize that somebody, perhaps that nebulous and generally nefarious experimenter usually featured in this sort of argument, has marked each junction with an arrow pointing either left or right. Lacking any better idea, you follow these arrows and, lo and behold, soon find your way out of the maze.
Now consider a robot facing the same task. It has rudimentary visual processing capability, such that a shape like ‘←’ being registered by its optical sensors causes it to swivel 90° to the left, while ‘→’ causes a corresponding turn to the right. The robot will perfectly recapitulate your performance in navigating the maze, turning right or left whenever the appropriate symbol ‘tells it to’.
But nevertheless, there’s a key difference: when you turn right, you do so because you know that ‘→’ means right; when the robot turns likewise, it’s because the visual stimulus sets up a certain pattern of voltages in its optical receptor that ultimately leads its servo motors to be activated in a certain way. We could just as well have the robot be remote controlled: pushing the button for ‘turn left’ then doesn’t send a message to the robot that tells it to turn left, it simply causes it to turn left.
Causality, here, works in the same way that the pattern of rocks on a steep slope causes a tumbling stone to jump here or there—it’s not that the rocks tell it to move a certain way, that their placement has a certain meaning to the stone that it translates into action, it’s just a matter of banging up against them. Likewise, the photons reflected from the arrow bang up against the robot’s sensor, ultimately causing it to turn.
The robot, and the constructor above, lacks metacognitive awareness of the symbol’s meanings: while we can say, “‘→’ means ‘right’ to the robot”, it is itself blissfully unaware of that fact; it is simply caused to turn right by the symbol’s presence. In contrast, over and above simply being stimulated to show a certain behavior, we are aware of the fact that it’s the symbol’s meaning that prompts our actions. ‘→’ means ‘right’ to me, and furthermore, I know that “‘→’ means ‘right’ to me”. It is this self-reflective property that is absent from the robot’s interpretations of symbols.
Homunculus, Know Thyself!
So, how does this self-reflective awareness of a symbol’s meaning come about? A plausible suggestion might be that external symbols, which we encounter in the world, are somehow translated into internal, or mental, symbols. This is the doctrine of representationalism: we think about things by manipulating mental symbols referring to these things.
But there’s a catch: if we need a mental symbol to decode the meaning of some external symbol, how do we decode that mental symbol? It’s as if we had, in our ‘mind’s eye’, a sort of internal viewscreen upon which data regarding the external world is represented. But then, it seems, we need to postulate some entity—some homunculus—that looks at that screen, and interprets what it shows—but then, this begs the question: how does the interpretation in case of the homunculus work? Recall, we had invoked the internal representation—the Cartesian Theater, as the philosopher Daniel Dennett calls it—to make sense of our ability to interpret external signs. If this is the right way to explain interpretation, then it seems the homunculus will need its own inner representation, interpreted by its own homunculus, which will in turn need an inner representation, and so on: we encounter an infinite regress of homunculi, and each one’s power of interpretation depends on that of the homunculus one rung up the ladder (see Fig. 1).
However, there is a way out, first formulated by the great Hungarian mathematician and polymath John von Neumann, albeit in response to the question of self-reproduction and growth in complexity. Suppose we just tried to ‘brute force’ giving the constructor knowledge of itself by affixing its own blueprint to it (Fig. 3).
Armed with that blueprint, the constructor creates a faithful copy of itself. Does that mean it now has ‘knowledge’ of itself, too? Unfortunately, things are not that simple: there is an aspect of itself it has not duplicated—namely, its ability to duplicate itself. If the ability to duplicate itself is interpreted as its knowledge of itself, then this means that it doesn’t know itself as a self-knower. But this is exactly the crucial metacognitive awareness we’re trying to capture. It’s then easy to illustrate how we run into the homunculus issue by further continuing this ‘brute force’-attempt. For suppose we now include a blueprint for the constructor’s blueprint.
The resulting second-generation constructor, then, is capable of constructing a copy—but again, not capable of constructing a copy able to copy itself. ‘Self-knowledge’ of such a construction runs out; to enable an open-ended process of self-reproduction, we would have to infinitely nest blueprints—running, again, into the homunculus problem (Fig. 4). If the first-generation constructor were to take what’s shown on its blueprint as a faithful representation of itself, it would conclude that it can’t give rise to a self-reproducing entity, as it would ‘believe’ itself to be the second-generation constructor—thus, it would necessarily be wrong about itself, and hence, not have any genuine self-knowledge whatsoever.
Von Neumann: Leapfrogging Infinity
Von Neumann saw that the way out of this mess of infinitely nested homunculi is to introduce another capability, that of copying. Thus, let us introduce a duplicator, which is defined by its ability to take any blueprint, and produce a faithful copy of it (‘transcribing’ it) (Fig. 5).

Finally, we need a third element, the supervisor, which we can think of as a control unit that activates first the duplicator, then the constructor. For simplicity, we will think of this part as simply a computer. The combined action of this assembly on a given blueprint, then, is to both transcribe and interpret it (Fig. 6)—to manipulate it on a syntactical as well as semantical level. It’s this separation of powers that ultimately points the way out of the homunculus regress.

Now, all we need to do is to feed that assembly its own blueprint. In first duplicating, then interpreting that blueprint, we get a faithful copy of the original, endowed with all the same faculties of self-reproduction / self-knowledge (Fig. 7). The homunculus has been successfully exorcised: effectively, the regress has been collapsed by eliminating the distinction between symbol and interpreter. The von Neumann replicator can ‘look at’ itself: it is fully aware of its own self-representational capacities. It is a system that has a full theory of itself—technically speaking, it can prove arbitrary theorems about its own properties, simply by examination of its own ‘source code’.
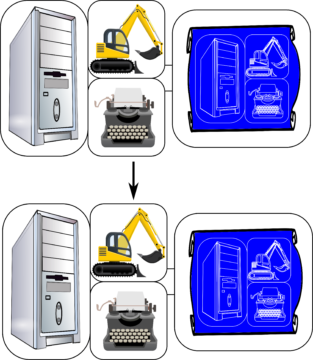
But we’re not quite done, yet. The von Neumann mind interprets itself as a symbol for itself, and is aware of this—it possesses the metacognitive awareness the bare constructor lacked; it is a symbol of itself, and it knows itself to be a symbol of itself. But this is a rather barren notion of representation; all it yields, it seems, is navel-gazing introspection. As a symbol, it is an empty shell, lacking any true symbolic content. How to turn its gaze outwards, into the world?
Meaning Evolves
Von Neumann’s design has a further aspect, which is the notion of heredity—having so far articulated the bare machinery of self-reproduction, we can now introduce arbitrary additional elements, which need not have any functional relevance to the reproductive process as such. Furthermore, by introducing variations of the blueprint (the ‘genotype’), we obtain variations in the form of later generations (the ‘phenotype’)—meaning, we can introduce hereditary change into the assembly. If we then couple this with an appropriate selection mechanism, such that certain replicators replicate more successfully than others, we have a design which evolves—adapts itself over successive generations to its surroundings (Fig. 8).
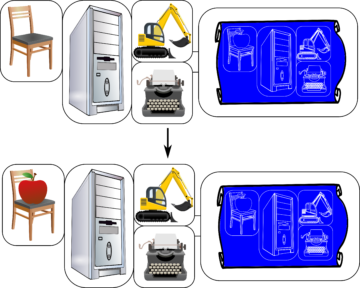
Now suppose that this variation is coupled to changes in the environment. For instance, suppose that the above evolutionary process occurs within the brain of some agent, patterns reproducing themselves, and by virtue of this, possessing knowledge of themselves. We might imagine these patterns shaped by environmental influences: the data received via the agent’s senses sets up certain conditions within its brain—certain patterns of neuron-excitations, say, or logic circuits opening and closing. These conditions, we may suppose, then decide which replicators thrive, and which are outcompeted. Ultimately, those that survive represent, in some sense, a ‘best fit’ to the sensory data the agent receives, and thus, to the environment it finds itself in.
Selection shapes the selected entities according to their environment—think about the dolphin’s streamlined shape indicating its aquatic surroundings, or the giraffe’s elongated neck indicating the location of its food. Thus, the replicator that fits the environment best, in that sense, represents the environment through its form; and in being aware of its form via the self-reflective von Neumann process, knows itself as a representation of the environment. Via variation and selection, the symbol is ‘shaped’ by the environment; and, in knowing its shape, is literally informed of this environment. In this way, the empty, self-reflecting container acquires its symbolic content.
Now suppose that, based on its shape, the replicator causes the agent to perform certain kinds of action in the world. Say there’s a certain shape that indicates there’s an apple nearby; the replicator then knows of itself that it has that shape, and may, for instance, initiate a motion of grabbing for the apple. We can, in a sense, imagine the symbol itself to do the grabbing, much as the operator of a crane originates the latter’s purposeful behavior—the crane operator lends their intentionality to the crane as a whole, and the symbol does the same with the agent whose brain it has come to colonize.
Let’s now circle back to the beginning. What happened when you read my words, (hopefully) understood them, and (perhaps) translated them into action, if the above account is anywhere close to right, was that your perception of these words set up a certain environment within your brain, within which replicators evolved. For instance, the words ‘turn your head to the left’ facilitate the selection of a certain replicator that would, if put into the control seat, indeed cause your head to be turned to the left; but that, moreover, knows this about itself. Its ability to examine its own blueprint affords it the metacognitive awareness we found the simple symbol-following robot lacked. It’s in this sense that we not just behave in accordance with symbolic prompts, but furthermore, know what the symbols mean.
There are some further elements to this story, which I plan to elaborate on in future posts. Most of the above is based on two papers published in 2015 and 2018 (links go to publicly-available preprint versions).
All images were created using public domain clipart from Openclipart.org. Image sources: [1], [2], [3], [4], [5], [6], [7], [8]