
by David J. Lobina

A provocative title, perhaps, but as the sort-of cognitive scientist that I am, I find most of the stuff that is published about Artificial Intelligence (sic) these days, especially in the popular press, enough to make one scream, so perhaps some contrarian views on the matter are not entirely uncalled for. And in any case, what the title of the post conveys is more or less correct, though to be more precise, and certainly less bombastic, the point I want to make is that it is really a moot question whether modern AI algorithms can be sentient or sapient.
So. What sort of coverage can make one scream, then? Anything these days, especially since the release of GPT-3, let alone ChatGPT (and God help us when GPT-4 comes out), the large language models (LLMs) so popular these days, which are ever so often claimed to have matched the linguistic, and even cognitive, skills of human beings. This is not a new claim, of course; in 2019 there were already articles out there arguing that AI had not only surpassed human performance on rule-based games like chess, which at the very highest level of play involve carrying out huge numbers of calculations, thereby constituting the right sort of task for a computer, but also in terms of human understanding.
The situation is much worse now, though. LLMs will spell doom for certain professions, it seems, including university lecturers; or at least it will bring an end to all those dodgy companies that provide essay-writing services to students for a fee, though in the process this might create an industry of AI tools to identify LLM-generated essays, a loop that is clearly vicious (and some scholars have started including ChatGPT as a contributing author in their publications!). LLMs have apparently made passing the Turing Test boring, and challenges from cognitive scientists regarding this or that property of human cognition to be modelled have been progressively met.[i] Indeed, some philosophers have even taken it for granted that the very existence of ChatGPT casts doubt on the validity of Noam Chomsky’s Universal Grammar hypothesis (Papineau, I’m looking at you in the Comments sections here). We have even been told that ChatGPT can show a more developed moral sense than the current US Supreme Court. And of course the New York Times will publish rather hysterical pieces about LLMs every other week (with saner pieces about AI doom thrown in every so often too; see this a propos of the last point).
Nothing happens in a vacuum, however, and there’s been plenty of pushback on many of these pronouncements – or, at the very least, more careful and sceptical evaluations of what LLMs do and are. The cognitive scientist Gary Marcus has been the most active when it comes to showing that, contrary to some of the claims referenced above, LLMs are inherently unreliable and don’t actually exhibit many of the most common features of language and thought, such as systematicity and compositionality, let alone common sense, the understanding of context in conversation, or any of the many other unremarkable “cognitive things” we do on a daily basis. In a recent post with Ernest Davis, Marcus includes an LLM Errors Tracker and outlines some of the more egregious mistakes, including the manifestation of sexist and racist biases, simple errors when carrying out basic logical reasoning or indeed basic maths, in counting up to 4 (good luck claiming that LLMs pass the Turing Test; see here), and of course the fact that LLMs constantly make things up.
Much has in fact been made of the factual errors and fabrications LLMs come up with – some call them hallucinations, somewhat mistakenly, I think – and I have experienced this myself when I interacted with GPT-3 some time ago, as the algorithm invented academic papers, people, and meetings out of nowhere. Of more interest to me in my interaction with GPT-3, however, was the fact that the model clearly doesn’t make any use of what linguists call “knowledge of language”, that body of information that underlies our linguistic abilities, as shown by its inability to react to the details of individual sentences like we do (this is also true of ChatGPT, or GPT3.5; see John Collins’s comments in one of the links included supra). That is, LLMs know nothing about the meaning of words, for no semantic model is involved; the models do not put sentences together based on how sentences must be structured (i.e., in terms of syntax), a core property of language; and such models clearly are oblivious to any pragmatic consideration – as in the pragmatics of language, which includes the ability to track people’s intentions, keeping to the subject matter in accordance to the context, etc.[ii]
And this brings me to the point at the heart of the problem (well, my problem): in all the exalted conversation about LLMs there is a great disconnect between what the models come up with – their output – and the very nature of the models that reach such outputs. I am not referring to what is sometimes called the explainability of AI, an issue which is centred on an attempt to bridge the gap between the internal operations of the relevant AI models and the outputs they yield, with the view to improve the decisions of an algorithm that may well decide whether to grant you a loan or not (and with the view, moreover, to not be sued as well as to comply with some of the regulation on this very issue that the European Union is preparing; the Brussels effect and all that). No, I mean the more fundamental point of what modern AI models actually look like – that is, what such models are and do tout court.
AI is very often understood as a computational system that shows intelligent behaviour – for instance, complex behaviour conducive to reaching specific goals. So understood, classical AI models from the 1940s or so, and until the so-called AI Winter in the 1970s, for the most part involved symbol-manipulation systems. Such systems employed many of the constructs commonly found in formal logic and were, in fact, inspired by the theories of human cognition then (and still now) dominant (namely, the representational/computational paradigm of cognitive science).
There are, as a matter of fact, various approaches to AI, from logic- and knowledge-based ones to purely statistical methods involving Bayesian inference (after the Reverend Thomas Bayes, whose now widely-used theorem inspired such methods). Utterly dominant today, however, is the use of machine learning algorithms, and in particular deep learning methods. Indeed, by AI these days it is the artificial neural networks of such approaches that people have in mind, and hardly any of the other methods shown in the figure below.
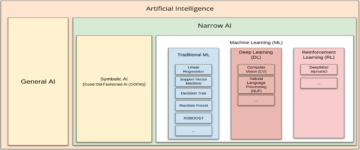
Loosely based on the neurons of biological brains, though it does not constitute a theory of how the brain works, machine learning was first thought up in the 1950s but was given some proper impetus in the field of cognitive science in subsequent decades, where so-called “connectionist networks” (or c-nets), a predecessor of modern machine learning networks, were argued to be appropriate models of human cognition, from language and vision to much else.
In broad outline, machine learning is the study of algorithms that improve automatically through experience. Closely related to statistics and probability theory – in early years, in particular, to generalised linear models (i.e., regressions) – the aim of machine learning models is to find generalisable predictive patterns, whereas the aim of a regression model, for instance, is to draw population inferences from a sample. Somewhat less roughly, machine learning involves creating a model that has been trained on a set of data (the so-called training data), and from this trained model the method attempts to process additional data to make predictions (a training-then-inference cycle).
As mentioned, the method most commonly used is based on artificial neural networks (in short, NNs), which can be said to “learn” by considering the examples that it is inputted. Populations of neurons (or nodes) in such NNs communicate with each other, thereby implementing various connections (these connection are established by real numbers, for we are talking about a mathematical model at the end of the day). The output, that is to say, the intended outcome of the overall process (in effect, a set of neurons), is computed by some non-linear function of the sum of its inputs, and if there are multiple hidden layers mediating between the input and output neurons, then we are dealing with a deep learning model, as outlined in the figure below, though of course very roughly so.
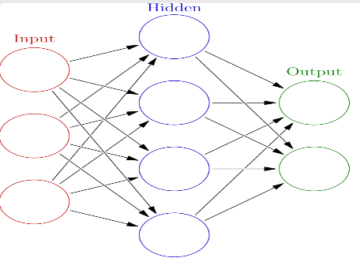
In effect, NNs track the various correlations between inputs and outputs that the models find in the training dataset, and such “pattern finding” algorithms have proven to be very useful in all sort of tasks, such as language generation, image classification, etc. And hence, I suppose, the ubiquity of machine learning and deep learning, with an ever increasing number of use cases and applications out there. It is important to note, however, that even in those cases in which intelligent behaviour seems to be displayed by a machine learning network, all that the system is effecting is a correlation between an input and an output – that is, it finds statistical patterns in the data – with no understanding of the underlying cause of an event, and often manifesting no transparency as how the correlations were calculated (the lack of explainability mentioned earlier).
The overall picture certainly applies to LLMs such as ChatGPT. LLMs generate strings of elements such as words based on word combinations from the training dataset; the models do so by calculating so-called embeddings and binding relations (no need to get into this); and, thus, they are a sort of cut-and-paste tool, where every paraphrase is ultimately grounded on something a human once said or wrote (the training dataset)[iii] – in sum, ChatGPT is a text generator, a system that predicts the next word in the string that has been given as input. A very sophisticated auto-completion tool; no more, no less.[iv]
Coming back to the issue of the sentience and sapience of AI models (sic: machine learning models), two points are worth emphasising. Regarding sentience (and consciousness), and whatever exactly this slippery concept may turn out to be, what we do know about sentience is that it is dependent upon a specific neurobiology, that there is no reason to believe in any sort of substrate independence for sentience. As the philosopher Ned Block has aptly put it (I am combing two different tweets here, but let it pass):[v]
There is one obvious fact about the ONLY systems that we are SURE are sentient: their information processing is mainly based in electrochemical information flow in which electrical signals are converted to chemical signals (neurotransmitters) and back to electrical signals…If fish are sentient, it is because of their neurobiology, not their facility in conversation.
In other words, no sentience with the wrong neural substrate, and sentience is not demonstrable through conversation, or a simulation of a conversation (via a computer terminal or not). And the same sort of story applies, mutatis mutandis, as my favourite philosopher used to say, to sapience, whatever that turns out to be too, for machine learning models carry out input-output correlations and human cognition is not like that. Linguistic knowledge, to stick to language, involves symbolic representations, be these in phonology or syntax, that combine with each other in structure-dependent ways – it is structured knowledge through and through. Thus, it is quite wrong-headed to ascribe to LLMs any kind of equivalence to basic features of our knowledge of language, let alone any sort of sapience, for the very simple reason that there is, quite literally, nothing cognitive in those networks. Much as in the case of sentience: no sapience with the wrong cognitive mechanisms (this is the mutatis mutandis bit).
The point about equivalence brings me to the figure of Zenon Pylyshyn, a prominent cognitive scientist who passed away last December, and a collaborator of Jerry Fodor on many of the issues I have touched upon in this blog since I started writing for 3 Quarks Daily. In his 1984 book, Computation and Cognition, a particularly influential work for me in my early years in academia, Pylyshyn draws a distinction that is quite relevant here. This is the distinction between the weak equivalence of two computational systems, and their strong equivalence. Weak equivalence obtains when two systems compute the same input-output function, or exhibit the same external behaviour, as in the Turing Test, effectively (see endnote i), whereas strong equivalence obtains when two computational systems go beyond this and accomplish weak equivalence by executing the same algorithm in the same architecture. Pylyshyn always insisted that cognitive scientists were in the business of establishing the strong equivalence of our models to human cognition, a lesson that modern AI engineers would do well to heed, as contemporary machine learning models can, at most, accomplish only weak equivalence to human cognition, no matter how much such models are eventually scaled up – it really is not a matter of size.[vi]
Why would it be otherwise, anyway? And why, perhaps more importantly, do so many people see sapience in what are effectively only input-output pairings, transmitted through entirely manufactured channels to boot? I can only speculate, but I would venture to suggest that there is projection of mentality here. Just as we regularly ascribe mental states such as beliefs, desires, and intentions to other people (and to animals), which allow us to explain and predict the behaviour of others (this is usually called folk psychology, a central part of Fodor’s account of thought that I have discussed so often in this blog), it may well be that this mental-ascription ability is being extended to artificial agents too, be these robots or algorithms. The problem is that in this case we are not at all justified in doing so, for it is not a cognitive agent we are dealing with, but a computing system that tracks patterns we humans have created in the past, and it doesn’t even work, for we are not able to explain, let alone predict, the behaviour of any AI algorithm in this way (as some users of ChatGPT may have noticed, LLMs have no memory, and given that they are probabilistic systems, their processes start anew with each prompt and are thus liable to give different answers to the same questions, and constantly so).
There are a few more things to say about the topic, especially regarding the use of technology in general, some possible modifications and improvements of machine learning networks (see endnote vi), other applications such as the generation of art, and of course the ridiculousness of fantasies of AI doom, but it is a bit late in the day (literally!) and the post is already long enough. I will come back to these issues next month, and for the time being I will let you work out the meaning of all those “sics” I have included in the post.
[i] Unfortunately, but perhaps unsurprisingly, the way the Turing Test is usually discussed by the press or, for that matter, by experts in AI, has little to do with how Alan Turing saw things. As the entry on the Turing Test at the Stanford Encyclopaedia of Philosophy website puts it:
The phrase “The Turing Test” is most properly used to refer to a proposal made by Turing (1950) as a way of dealing with the question whether machines can think. According to Turing, the question whether machines can think is itself “too meaningless” to deserve discussion (442). However, if we consider the more precise—and somehow related—question whether a digital computer can do well in a certain kind of game that Turing describes (“The Imitation Game”), then—at least in Turing’s eyes—we do have a question that admits of precise discussion. Moreover, as we shall see, Turing himself thought that it would not be too long before we did have digital computers that could “do well” in the Imitation Game.
So, then, the Turing Test is really about whether a machine (these days, an algorithm) can play the Imitation Game, but such evidence can only provide indirect evidence, at best, on properties such as sentience and sapience. This is enough to make my point already, but I wish to spell this out properly in the main text. As an aside, in my experience of dealing with people from the AI sector as an analyst in recent years, very few people have actually read Turing’s 1950 paper, nor does anyone seem to know that it was published in a philosophy journal (Mind).
[ii] Needless to add, the case of LLMs has nothing to say about Chomsky’s Universal Grammar hypothesis.
[iii] It is commonplace in some quarters to dismiss machine learning as an exercise in curve fitting, by which it is meant the construction of a curve, or mathematical function, that best fits a series of data points, much as a regression does. The complaint about machine learning, traceable to Jadea Pearl, is possibly still a valid one, and it is certainly one of the reasons that AI models exhibit so many sexist and racist biases – these biases are in the training data and the models will find the relevant patterns.
[iv] To be more accurate, LLMs are large networks of matrix/tensor products, but they are not fed any semantics or facts about the world, truth considerations are not part of the training process, and they really are all about patterns of word/letter/sound co-occurrences. I should add that the NNs underlying the GPT models include attention mechanisms, layers that learn which parts of the data should be focused on during training in order to adjust the weights between words (or more accurately, word embedding; see here). Networks with such layers are called transformers, and that’s why GPT stands for Generative Pre-trained Transformer.
[v] And I’m quoting from social media; let that pass too. At least it is not LinkedIn (sic).
[vi] Pylyshyn, along with Fodor, was a fierce critic of connectionist models of cognition (recall that c-nets are NNs, and thus basically machine learning models), and whilst they rejected such networks as appropriate models for cognition, they were nonetheless open to the possibility that these networks could constitute an account of how cognition was implemented in the brain; I’m much more sceptical about this, but this is a topic for another time. It worth adding that Gary Marcus has argued in favour of hybrid machine learning models, that is to say models that include symbolic representations as well as a machine learning component, just as some prominent connectionists have done in the past, though this remains a no-no for many of the main AI players in the market (in some cases for ideological reasons, it seems to me; see here for some of the other ideas being floated around at present).